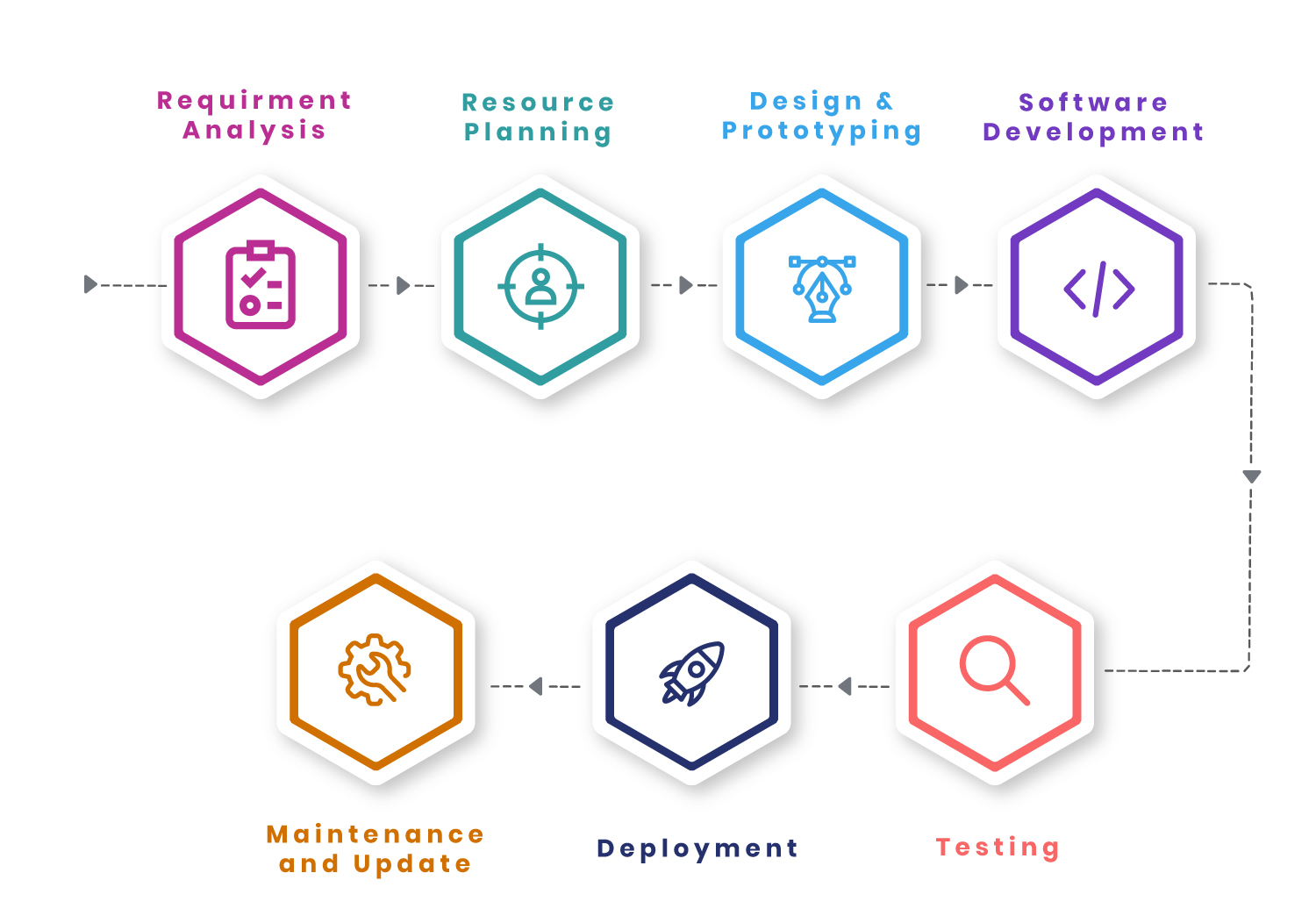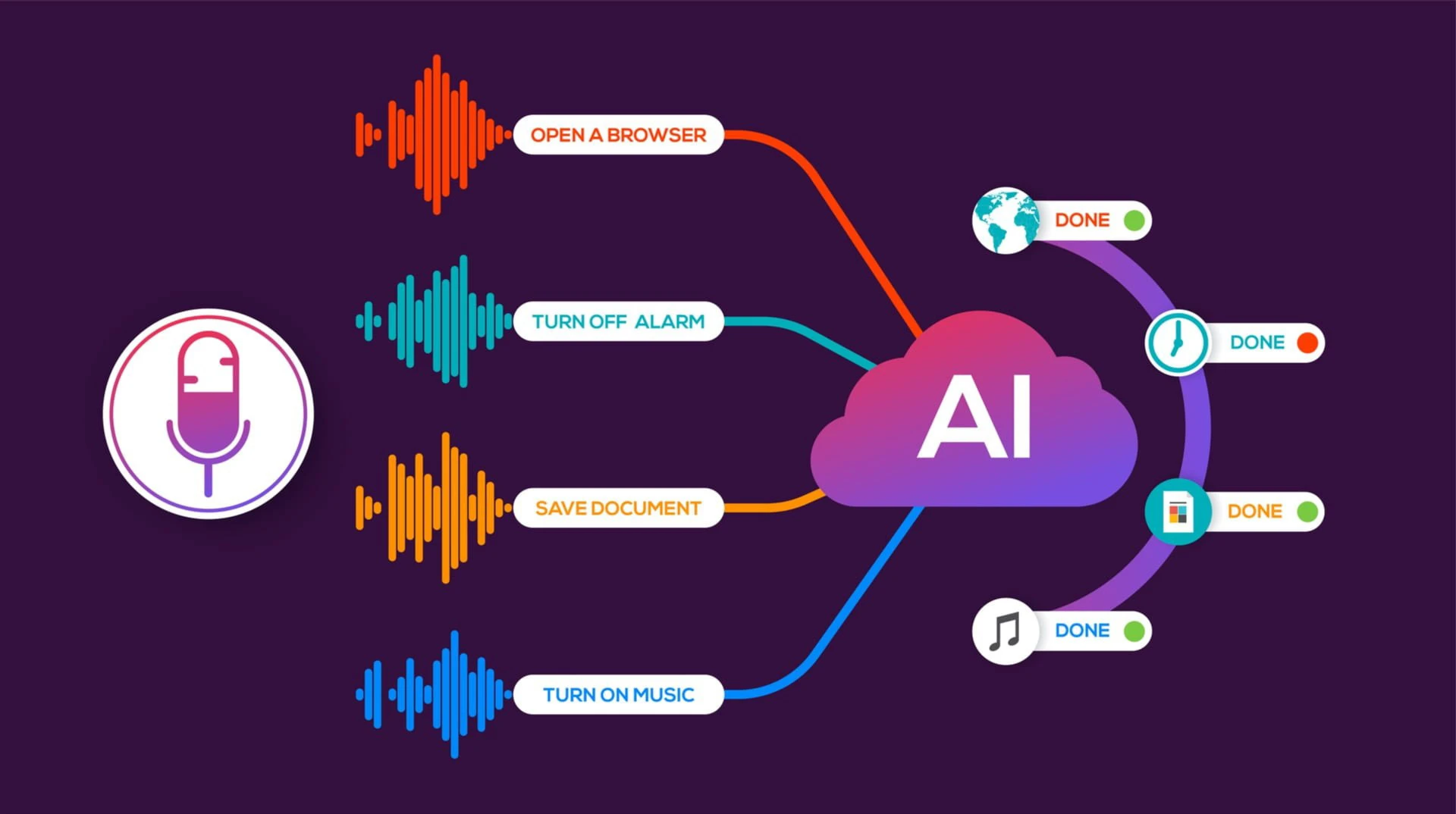
Text-to-Speech Service
Our approach begins with deeply understanding your business processes—whether it’s operations, sales, finance, customer service, or field management—and pinpointing where automation and intelligence can create the greatest value. We then design AI-driven workflows, chatbots, predictive models, and data engines that seamlessly integrate into your existing systems.
From automating repetitive tasks and extracting insights from documents to forecasting demand, detecting anomalies, and guiding teams with real-time recommendations, Nichetech transforms data into action.
The result is faster operations, fewer errors, smarter decisions, and teams that can focus on what truly matters—innovation, customers, and growth.
Drive Innovation and Efficiency with NicheTech's AI and ML Services
AI-Powered Applications:
Develop intelligent applications that leverage AI for personalized user experiences, task automation, and enhanced decision-making processes.
Machine Learning Models:
Design and implement ML models to analyze vast amounts of data, identify patterns, and make accurate predictions to improve business operations.
Natural Language Processing (NLP):
Create applications that understand and process human language, enabling advanced functionalities such as sentiment analysis, language translation, and chatbots.
Computer Vision:
Utilize AI to interpret and analyze visual data from images and videos, enabling applications like facial recognition, object detection, and image classification.
Chatbot Development:
Develop chatbots that provide instant, accurate, and personalized responses to customer inquiries, enhancing customer satisfaction and reducing response times. Create chatbots capable of understanding and responding in multiple languages to cater to a global audience.
Robotic Process Automation (RPA):
Automate repetitive and time-consuming tasks, freeing up your workforce to focus on more strategic activities.Implement RPA solutions to minimize errors and improve the speed of business processes.Reduce operational costs by automating tasks that would otherwise require significant human resources.Reduce operational costs by automating tasks that would otherwise require significant human resources.
AI-Powered Mobile and Web Apps:
Develop mobile and web apps that leverage AI to offer personalized recommendations and content to users, improving engagement and retention.Use AI to add advanced functionalities such as image recognition, voice commands, and natural language processing to your apps.
Predictive Analytics:
Harness the power of predictive analytics to forecast trends, customer behaviors, and market movements, aiding data-driven decision-making.
AI Integration:
Seamlessly integrate AI capabilities into your existing systems and processes to enhance efficiency, reduce costs, and improve overall performance.
Data Engineering:
Build and manage robust data pipelines to ensure your AI and ML models are fed with high-quality, reliable data for accurate insights and predictions.
Model Training and Optimization:
Train and fine-tune your AI and ML models for optimal performance, ensuring accurate and reliable results.
AI Consulting:
Benefit from our expert consulting services to identify AI opportunities, develop strategic roadmaps, and ensure the successful implementation of AI initiatives.
Maintenance and Support:
Provide ongoing maintenance and support to ensure your AI and ML solutions continue to operate smoothly and deliver consistent value.
Don't Just Develop, Innovate: Why AI is the Key to Your Next Project
Artificial Intelligence (AI) has emerged as a powerful tool, transforming industries and revolutionizing how we work. Here at Nichetech, a leading AI development company, we display the top reasons why AI should be at the forefront of your next project:
1. Power of Automation:
Repetitive tasks are a thing of the past. AI automates mundane processes, freeing your human workforce to focus on higher-level cognitive tasks that require creativity, strategic thinking, and complex problem-solving. This not only boosts productivity but also empowers your employees to contribute their expertise where it matters most.
2. Data-Driven Decision Making:
AI excels at analyzing vast amounts of data, uncovering hidden patterns and trends that might go unnoticed by the human eye. These insights empower data-driven decision-making, allowing you to optimize operations, identify new market opportunities, and make informed strategic choices with greater confidence.
3. Enhanced Customer Experience:
AI personalized customer interactions, predicts needs, and offers targeted recommendations. Chatbots powered by AI can provide 24/7 customer support, answer frequently asked questions, and resolve simple issues efficiently. This translates to a more delightful and personalized customer experience, fostering loyalty and brand advocacy.
4. Innovation and Competitive Advantage:
AI opens doors to groundbreaking innovations. From chatbots that revolutionize customer service to AI-powered product recommendations that boost sales, AI unlocks new possibilities for your business. By embracing AI, you can stay ahead of the curve and gain a significant competitive edge in your industry.
5. Improved Efficiency and Cost Savings:
AI streamlines processes, minimizes errors, and automates repetitive tasks. This translates to significant cost savings across various aspects of your business operations. Additionally, AI can help predict and prevent equipment failures, reducing downtime and associated costs.
6. Predictive Analytics:
AI's predictive analytics capabilities allow businesses to forecast future trends and behaviors based on historical data. This helps in proactive decision-making, such as predicting customer churn, optimizing inventory levels, and anticipating market demand, giving you a competitive edge.
Why Choose Nichetech for Your AI & ML Journey?
1. Local Expertise, Global Innovation : We bridge the gap between the Indian market's unique needs and cutting-edge advancements in AI & ML. We leverage our deep understanding of the Indian business landscape to tailor solutions that address your specific challenges.
2.Custom AI & ML Model Development: Our team of skilled engineers doesn't offer one-size-fits-all solutions. We build bespoke AI & ML models designed to address your specific industry and business goals.
Whether you need:
- Enhanced quality control with computer vision
- Powerful chatbots with natural language processing
- Smarter decision-making through predictive analytics
- Streamlined workflows with intelligent automation Nichetech has the expertise to craft the perfect AI & ML solution for you.
3.Focus on Explainable AI (XAI): Transparency builds trust. We utilize XAI methodologies to make your AI models interpretable. You'll understand how they arrive at decisions, fostering user confidence and ethical implementation.
4.Data Engineering & Management: Clean, organized data is the lifeblood of successful AI & ML projects. Our team meticulously manages your data infrastructure, ensuring it's readily available for model training and deployment.
5.Integration & Position: We integrate your AI & ML models seamlessly into your existing workflows and applications, maximizing their impact on your business operations.
6.End-to-End Services: From data analysis and model development to position and maintenance, we provide complete AI and ML development services to ensure perfect integration and optimal performance.
Contact us today to learn more about how AI/ML development can benefit your business and to explore our complete range of AI/ML solutions and services. At Nichetech, we have the expertise and experience to transform your vision into reality. Our team of AI engineers leverages advanced technologies and methodologies to develop custom AI solutions tailored to your specific needs. We don't just make models; We build partnerships, offering ongoing support and maintenance to ensure your AI solutions deliver long-term value.